Tasks#
The Task is the core functionality of the Inductiva API. It represents
everything about the computational workload you define and submit for
execution. Simply put, a Task is how your simulation is tracked, managed,
and updated in real-time.
When you submit a simulation, the API automatically generates a Task.
This gives you insights on the simulation status, including monitoring its progress and retrieving its outputs.
What This Guide Covers
This guide walks you through the entire lifecycle of a Task:
Task Creation: How a
Taskis generated when you submit a simulation.Task Execution: The stages a
Taskgoes through during computation.Task Lifecycle: A diagram illustrating the various states of a
Task.
By understanding these stages, you’ll gain a clear picture of how the Inductiva API handles simulations, making it easier to optimize your workflows and troubleshoot issues.
Task Creation#
A Task is automatically created whenever you submit a simulation to the
API by calling the run method on a simulator object. Each call to this
method generates a unique Task, even if the arguments remain identical.
This ensures separate executions for each submission of the same simulation.
Example: Submitting a SpliSHSPlasH Simulation
Here’s an example of how to create a Task by submitting a SpliSHSPlasH simulation
to the API:
# Running the SplishSplash simulator example
import inductiva
# Instantiate machine group
machine_group = inductiva.resources.MachineGroup("c2-standard-4")
machine_group.start()
# Download example input files
input_dir = inductiva.utils.download_from_url(
"https://storage.googleapis.com/inductiva-api-demo-files/"
"splishsplash-input-example.zip", unzip=True)
# Instantiate the simulator
splishsplash_simulator = inductiva.simulators.SplishSplash()
# Run the SPlisHSPlasH simulation with the required .json config file
task = splishsplash_simulator.run(
input_dir="splishsplash-input-example",
sim_config_filename="config.json",
on=machine_group)
print(task.id)
# Example output: i4ir3kvv62odsfrhko4y8w2an
Note that a subsequent call to splishsplash_simulator.run() with the same
input arguments would create a new, distinct task:
task2 = splishsplash_simulator.run(
input_dir="splishsplash-input-example",
sim_config_filename="config.json",
on=machine_group)
print (task2.id)
# Example output: k9muu1vq1fc6m2oyxm0n3n8y0
machine_group.terminate()
Every Task is assigned a unique alphanumeric identifier upon creation.
This identifier ensures that each task is distinct and can be easily referenced.
While it is possible to instantiate multiple Task objects using the
same identifier, doing so does not create duplicate tasks on the API.
Instead, all such objects point to the same underlying task, allowing you
to access and manage it across different sessions.
This mechanism is useful when you want to recreate a Task object to
retrieve information about tasks you created in previous sessions:
>>> import inductiva
>>>
>>> task1 = inductiva.tasks.Task("i4ir3kvv62odsfrhko4y8w2an")
>>> task2 = inductiva.tasks.Task("i4ir3kvv62odsfrhko4y8w2an")
>>> print(id(task1))
4410160112
>>> print(id(task2))
4389863104
>>> print(task1.id)
i4ir3kvv62odsfrhko4y8w2an
>>> print(task2.id)
i4ir3kvv62odsfrhko4y8w2an # Outputs the same task ID as task1.id
Task Execution#
Tasks run asynchronously by default, enabling you to continue interacting with the API without interrupting your code in the background, even as tasks run or are queued for execution. This asynchronous model also allows for batch submissions within a single session without waiting for each to complete, with the API efficiently distributing them across available computational resources for parallel processing.
You can configure how to wait for the task to end by either using the wait method or
the sync_context manager.
wait
You can turn a task into a blocking call by using the wait method.
This method will block the call, allowing your script to wait until the task comes
to a terminal status without affecting the remote simulation if it were locally
interrupted (ex. the script is abruptly terminated).
This is useful when you want to wait for the completion of a task before proceeding with some other operation (ex. downloading the output files):
# Block the call until the simulation completes
task.wait() # <- The remote simulation WILL NOT DIE if the local session is
# interrupted while waiting for the wait() call to return
sync_context
Alternatively, you can use the sync_context manager to ensure the remote simulation
terminates if your local session is interrupted while waiting for the wait call
to return (e.g., through a Ctrl+C command):
# Block the call until the simulation completes
with task.sync_context():
task.wait() # <- The remote simulation WILL DIE if the local session is
# interrupted while waiting for the wait() call to return
Task Lifecycle#
As a Task progresses through its lifecycle, its status changes to reflect
its current state. Understanding these states is essential for tracking
a Task’s progress and managing your simulations effectively through the API.
Below, you’ll find a diagram illustrating the possible states a Task can
move through and the transitions between them:
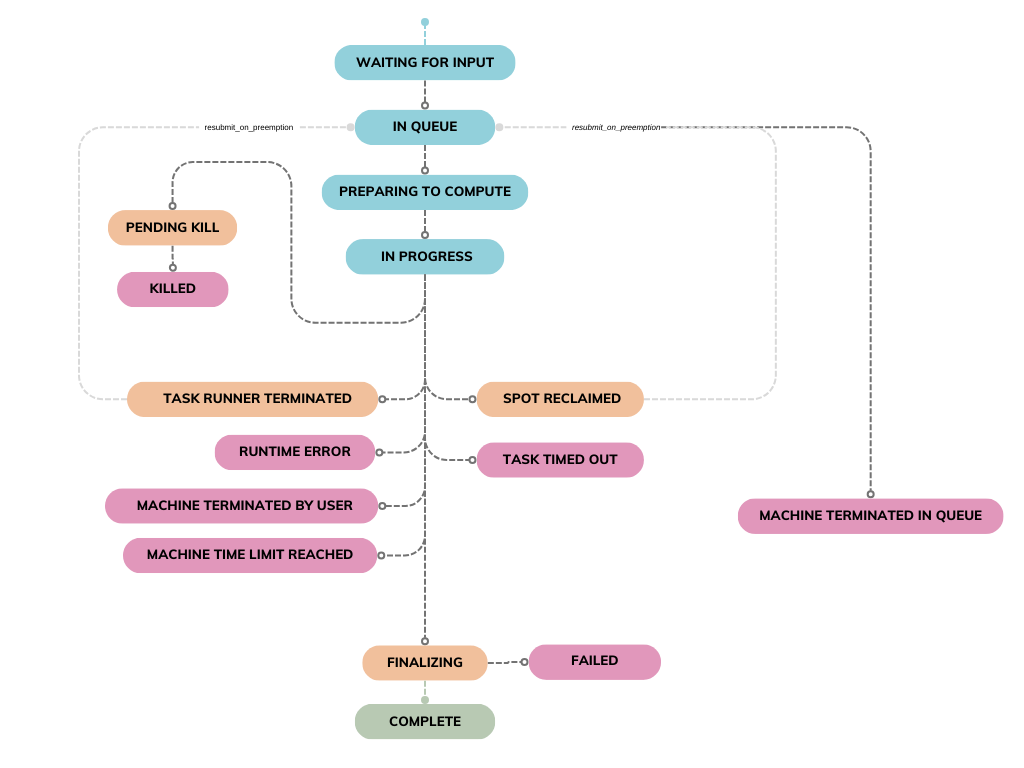
Here’s a breakdown of each state and the actions that lead to a state transition:
Status |
What happened? |
Why? |
Recommendations to overcome |
|---|---|---|---|
Waiting for Input |
Your simulation is waiting for all necessary input files. |
The task will not be queued until the required input files are uploaded. |
Wait for the input files to be uploaded. If there was an error while uploading the files, submit a new task. |
In Queue |
Your task is queued and waiting for a machine to become available. |
The task is submitted but hasn’t yet been picked up by an available machine. If you’ve queued more tasks than the number of machines in the machine group, they will be picked up from the queue as machines become free from processing previous tasks. |
Wait for the task to start, or kill it if no longer needed. To reduce waiting times, submit tasks to a machine group with more machines. |
Preparing to Compute |
Your task has been picked up by a machine. Required input files and container image are being downloaded in preparation to run the simulation. |
The task has been picked up by a machine, which is now setting up the appropriate assets to run your task. |
Wait for the simulation to proceed, or kill the task if no longer needed. |
In Progress |
The task’s inputs and container image have been downloaded, and the simulation has now started running. |
The machine has been set up with the requirements to run your simulation, which is now running. |
Wait for the simulation to proceed, or kill the task if no longer needed. You can monitor the simulator logs in real time using the |
Pending Kill |
Your request to terminate the task has been received and is awaiting execution. |
The system is processing your termination request for the running task. |
Wait for the task to be fully terminated. |
Killed |
The task has been successfully terminated as per your request. |
The task was terminated by user request. |
No further action is required. |
Machine Terminated in Queue |
The machine group where the task was enqueued was terminated before the task started. |
The task was still in the SUBMITTED status when the machine group was shut down. Since the task hadn’t started, there are no outputs or logs. |
Restart the task by submitting it to a new machine group or ensure the machine group remains active for future tasks. |
Spot Reclaimed |
The spot instances running your task were terminated, and the task has been interrupted. |
Spot instances were reclaimed by the cloud provider. If auto-resubmission is enabled, the task is re-queued and goes back to the SUBMITTED status. Otherwise, it stays in this state. |
If cost savings are a priority, spot instances are a good choice. For uninterrupted tasks, consider switching to on-demand instances. If the task is stuck, enable auto-resubmission or manually resubmit it. |
Failed |
The task failed due to an error in the simulator, likely caused by incorrect input configurations or an internal simulator issue. |
The simulator command returned a non-zero status code, indicating failure. |
Inspect the simulator logs (stderr and stdout) for more information. |
Finalizing |
The simulation’s commands have ended, and output files will be uploaded. |
The simulation commands have ran. Results will now be uploaded to the user’s storage. |
The task’s results will be uploaded to the user’s storage and the task will go to a terminal status. |
Task Runner Terminated |
The machine running your task was terminated due to internal reasons from the provider. |
The cloud provider terminated the executor unexpectedly. If auto-resubmission is enabled, the task is re-queued and returns to SUBMITTED status. Otherwise, it remains in this state. |
Enable auto-resubmission to automatically resubmit the task, or manually resubmit the task. |
Machine Terminated by User |
The task’s executor was terminated by you while it was running. |
The machine group was terminated after the task had started, but no outputs or logs are available because they are only saved once the task completes. |
If outputs are needed, avoid terminating the machine group mid-task. Resubmit the task and let it finish to retrieve logs and results. |
Machine Time Limit Reached |
The task’s machine was terminated because it exceeded its time-to-live (TTL) limit. |
The Machine Group’s TTL, defined by your quotas, was reached. This helps manage costs by ensuring resources don’t run longer than expected. |
Start a new Machine Group with a larger TTL and resubmit the task. If your quotas don’t allow a big enough TTL, talk to us. |
Runtime Error |
The task failed due to an error external to the simulator, such as low disk space. |
An exception in the machine running the task, most commonly due to insufficient disk space, caused the task to fail. |
Check the concrete reason for the error and act accordingly. If the the task failed due to insufficient disk space, resubmit the task in a machine group with larger disk space or configure the dynamic disk resize feature. |
Task Timed Out |
The task exceeded its configured time-to-live (TTL) and was automatically stopped. |
The task ran longer than the TTL defined in your quotas, which helps control costs by limiting how long a task can use shared resources. You can also set a TTL manually for better control. |
Resubmit the task and consider adjusting the TTL if more computation time is needed. |